NVIDIA RTX PRO 5000 Blackwell是 NVIDIA RTX 5000 Ada Generation 的升级迭代产品,其各项核心指标均针对 GPU 加速工作流的高性能需求进行了优化设计。无论是 CUDA 核心计算性能、实时渲染能力,还是 AI 推理效率,亦或显存带宽与容量的显著提升,均使得新一代 RTX PRO 5000 Blackwell GPU 能够轻松应对更复杂、更严苛的工作负载。
今天,我们带来全新 NVIDIA RTX PRO 5000 Blackwell 的深度评测,通过对比上一代 RTX 5000 Ada Generation,揭秘其性能与能效的全面升级。
测试环境
软件测试列表
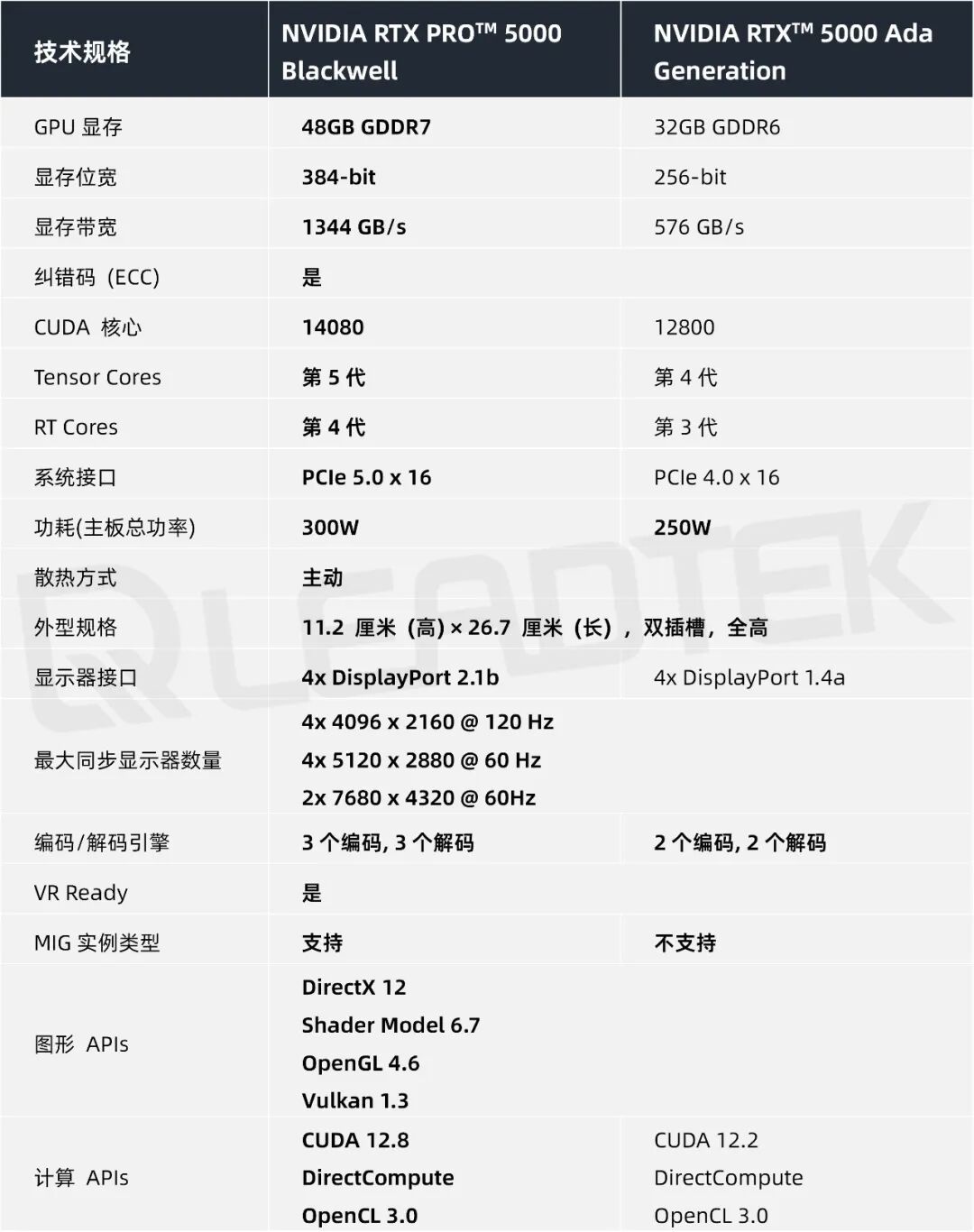
显卡规格
软件测试结果及分析
1. 实时渲染性能
1.1 FurMark
FurMark 作为 GPU 测试领域的经典工具,专用于 OpenGL 图形性能与系统稳定性评估。本次测试将聚焦两大核心维度:其一,通过 4K 分辨率实时渲染场景测试 OpenGL 图形处理性能;其二,在标准室温环境下监测 GPU 的散热效能与温度稳定性。
▲ RTX PRO 5000 Blackwell 测试结果截图
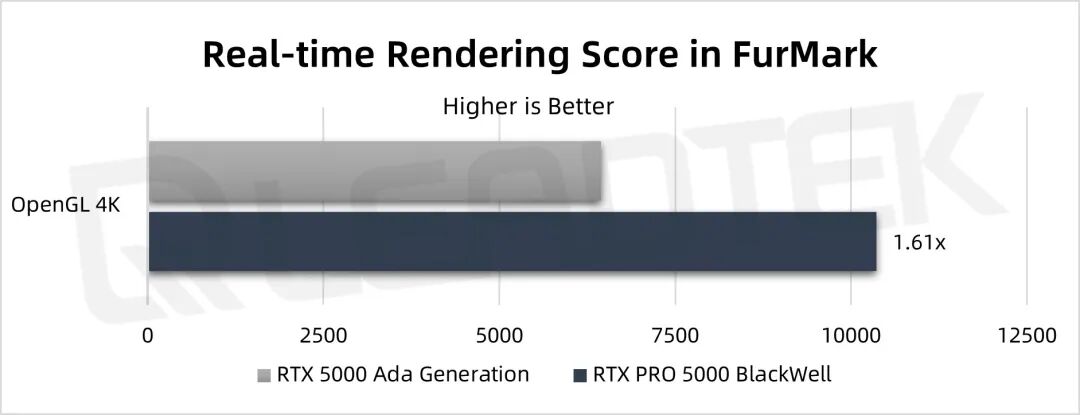
▲ 测试结果图表
从 FurMark 的实时渲染测试结果中可以看出,RTX PRO 5000 的 OpenGL 4K 性能是 RTX 5000 Ada 的1.61倍。通过长时间烤机(稳定性测试),RTX PRO 5000 的温度控制在 86 度以下。RTX PRO 5000 的目标控制温度是 86 度,GPU 控制功耗的阈值越高,越能发挥 GPU 的性能,在高负载下温度控制稳定。
1.2 3DMark
3DMark 作为专业级图形性能测试工具,专注于评估显卡在大型 3D 场景中的渲染能力。本次测试选取了两个高复杂度场景进行压力测试,同时涵盖 DirectX 与 Vulkan API 的性能表现,并通过 Port Royal 测试模块专项评估光线追踪性能。
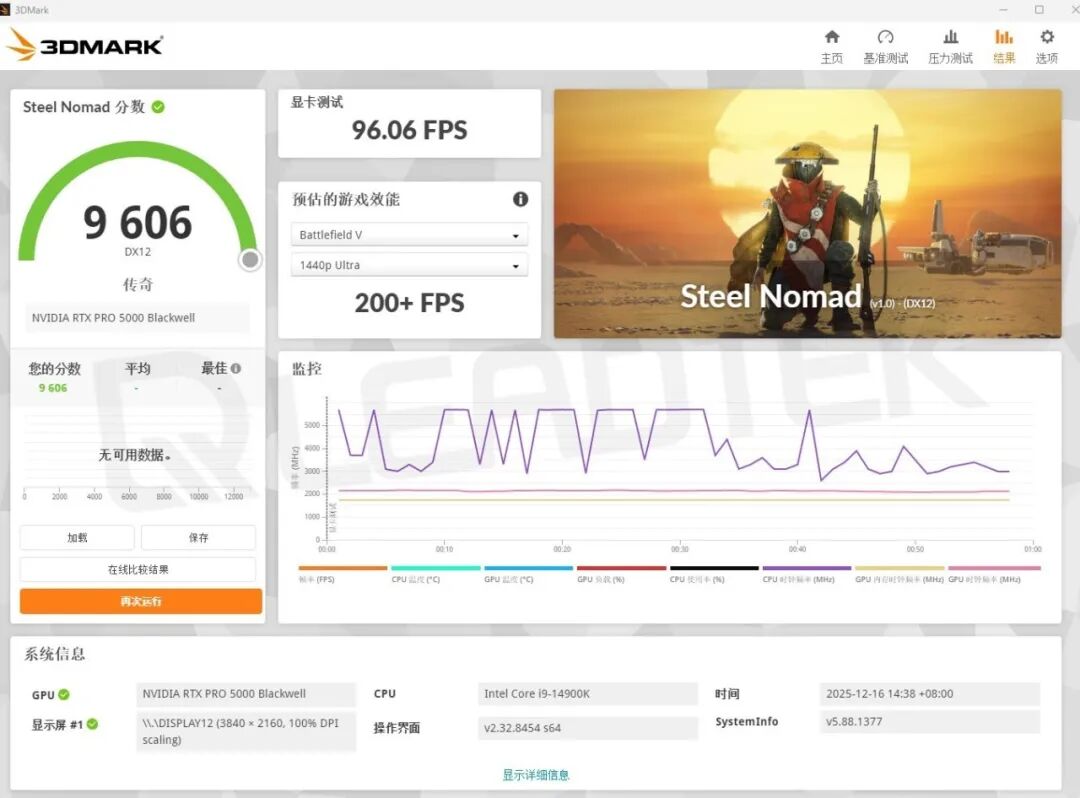
▲ RTX PRO 5000 Blackwell 测试结果截图
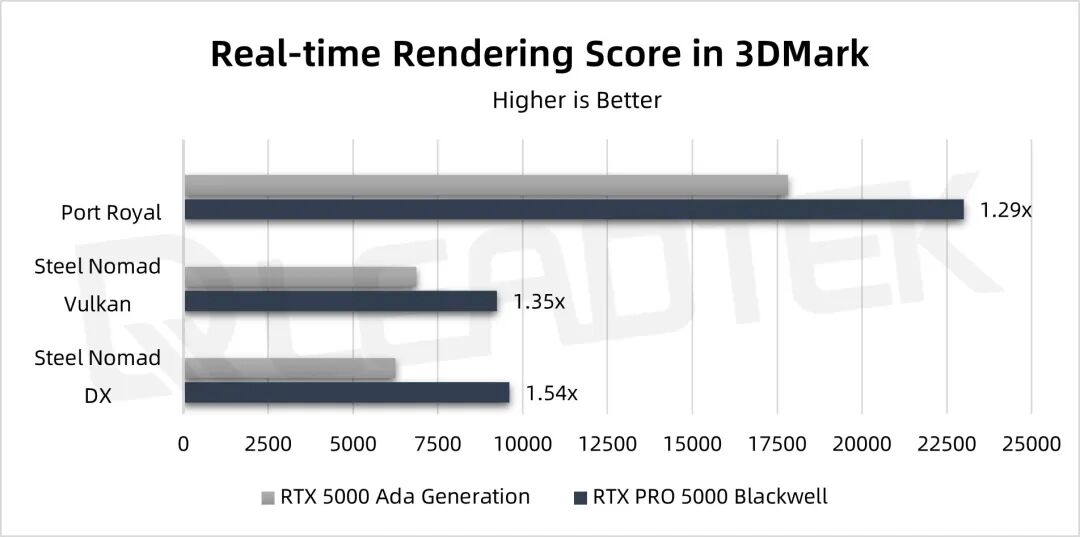
▲ 测试结果图表
从 3DMark Steel Nomad 的测试结果看,基于 DX 的环境 RTX PRO 5000 的性能是 RTX 5000 Ada 的1.54倍。Port Royal 光追的性能测试,RTX PRO 5000 的性能是 RTX 5000 Ada 的1.29倍。在 Steel Nomad Vulkan 的测试中 RTX PRO 5000 是 RTX 5000 Ada 的1.35倍。RTX PRO 5000 的 API 的管线渲染性能和光追性能都有了很大的提高。
1.3 NVIDIA Omniverse 工作流实时渲染
NVIDIA Omniverse 是一个包含 API、SDK 和服务的平台,使开发者能够将 OpenUSD、NVIDIA RTX 渲染技术和生成式物理 AI 集成到工业和机器人用例的现有软件工具和仿真工作流中。可以支持多人同时在线进行 3D 立体场景的协同搭建,支持丰富的 DCC 生态融合,可以支持光线追踪极具真实感的实时渲染。

▲ RTX PRO 5000 Blackwell 测试结果截图
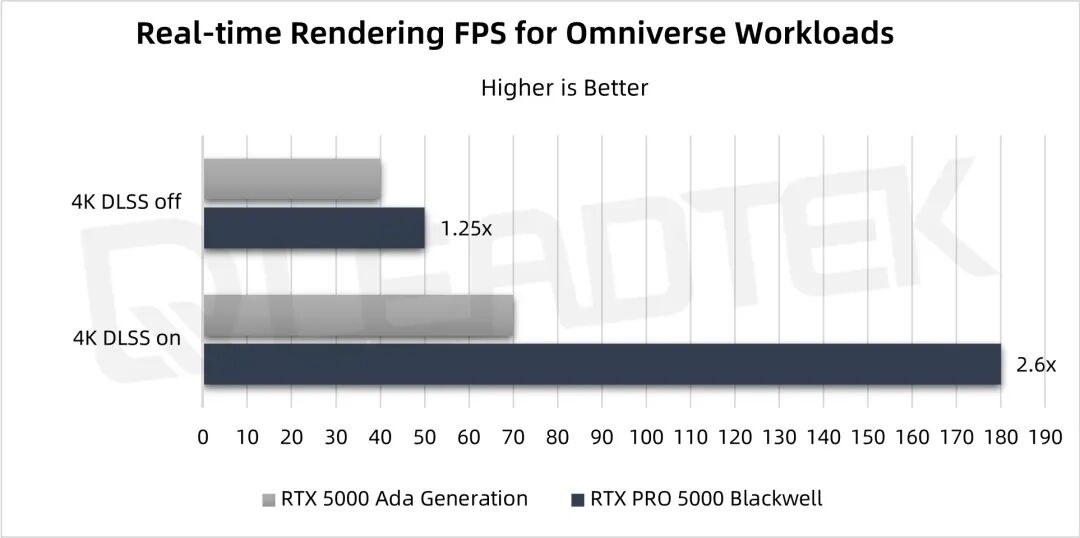
▲ 测试结果图表
▲实时渲染性能对比视频
在 Omniverse 实时渲染中,分别对开启 NVIDIA DLSS 和关闭 DLSS 的性能进行测试。针对相同场景的 4K 实时渲染,在启用 DLSS 时 RTX PRO 5000 的性能是 RTX 5000 Ada 的2.6倍,在不启用 DLSS 时,RTX PRO 5000 的性能是 RTX 5000 Ada 的1.25倍。
2. 离线渲染软件
渲染技术作为媒体娱乐、工业设计及建筑可视化等领域的核心工具,已广泛应用于影视特效、产品建模、虚拟建筑等场景。当前主流渲染器均支持 GPU 加速渲染,其执行效率直接取决于显卡的计算性能。
2.1 V-Ray Benchmark
V-Ray Benchmark 是一款免费的独立渲染速度测试软件,可精准评估计算机的渲染速度。它可以简单快速的测试两种渲染引擎:
> V-Ray GPU CUDA — GPU 渲染模式测试
> V-Ray GPU RTX — RTX GPU 渲染模式测试
本次测试不同 GPU 在不同 V-Ray 5 渲染引擎下的离线渲染性能,并记录最终得分。
▲ RTX PRO 5000 Blackwell 测试结果截图
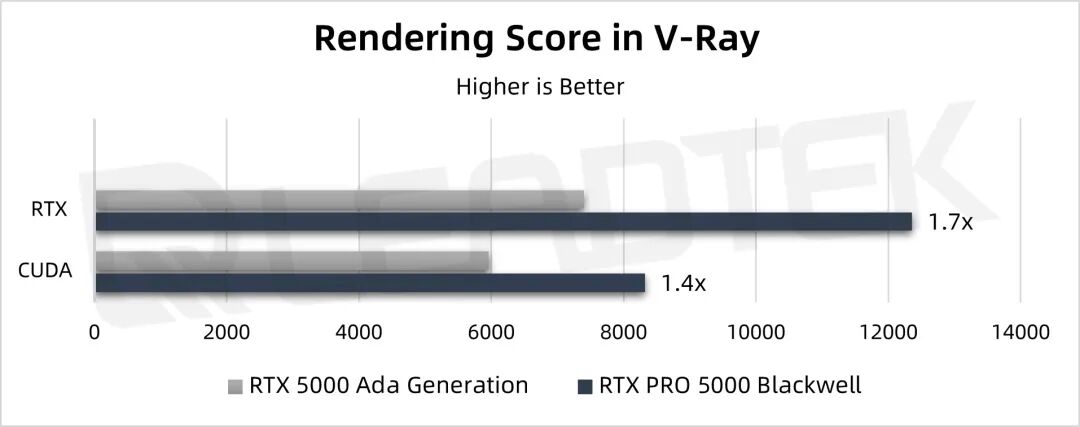
▲ 测试结果图表
在使用 RTX 渲染测试中,RTX PRO 5000 的性能都是 RTX 5000 Ada 的1.7倍。在使用 CUDA 测试中,RTX PRO 5000 的性能都是 RTX 5000 Ada 的1.4倍。
2.2 Blender Benchmark
在 Blender Benchmark 测试中,我们选取了 Monster、Junkshop 和 Classroom 三个标准场景进行渲染性能评估。
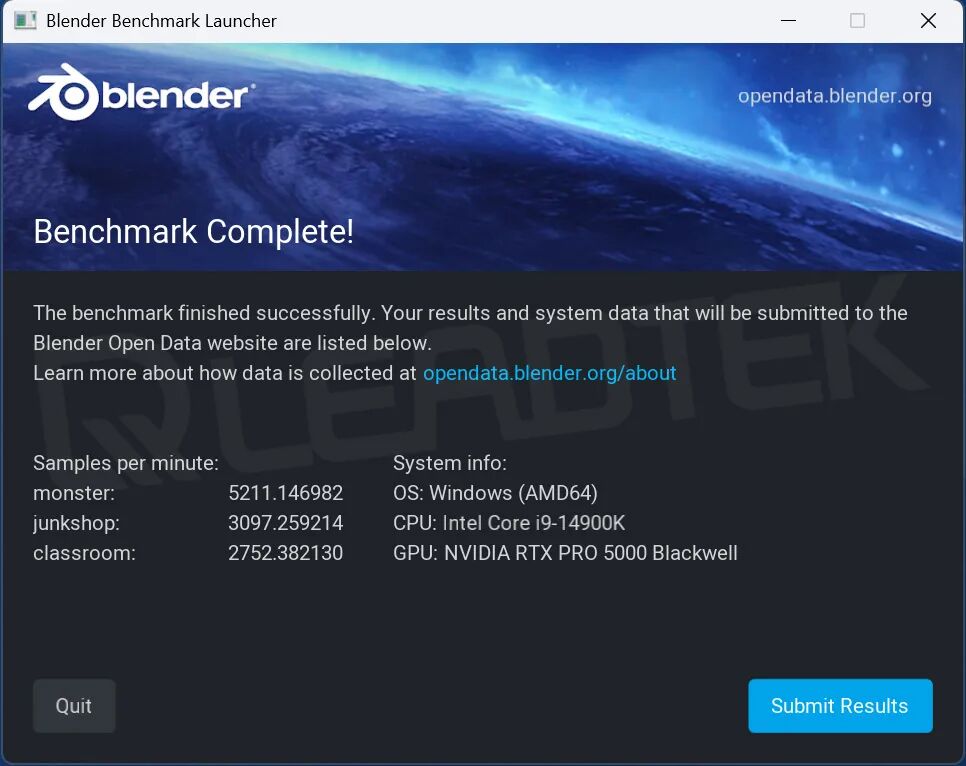
▲ RTX PRO 5000 Blackwell 测试结果截图
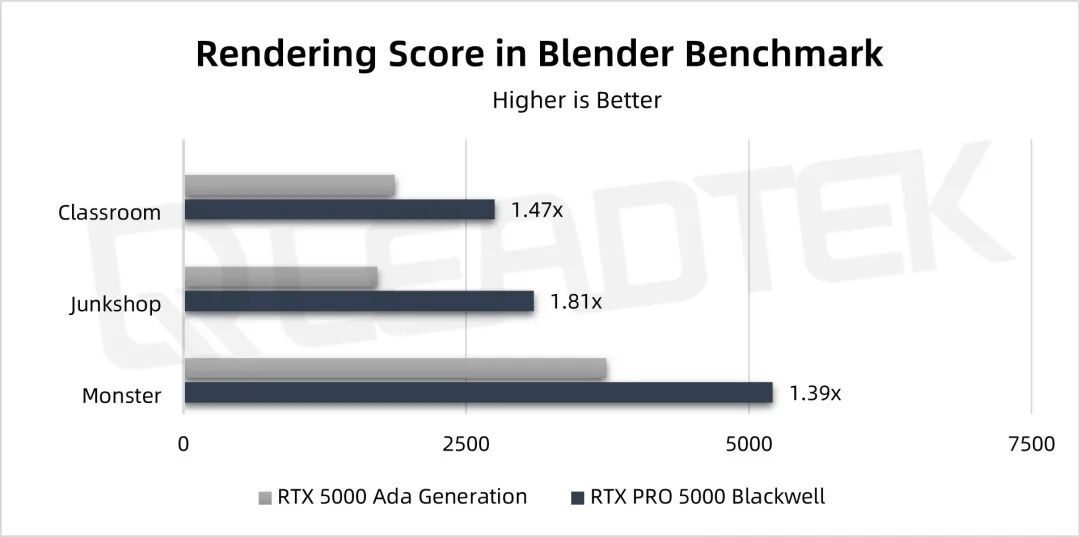
▲ 测试结果图表
其中在 Monster 场景的测试中,RTX PRO 5000 是 RTX 5000 Ada 的1.39倍。在 Junkshop 的测试中 RTX PRO 5000 是 RTX 5000 Ada 的1.81倍。在 Classroom 的测试中 RTX PRO 5000 是 RTX 5000 Ada 的1.47倍。
2.3 Octanebench
Octane 渲染器作为业界主流的 GPU 渲染引擎,率先支持基于光线追踪技术的实时渲染。我们采用其官方提供的基准测试工具(Benchmark)对 GPU 渲染性能进行量化评估。
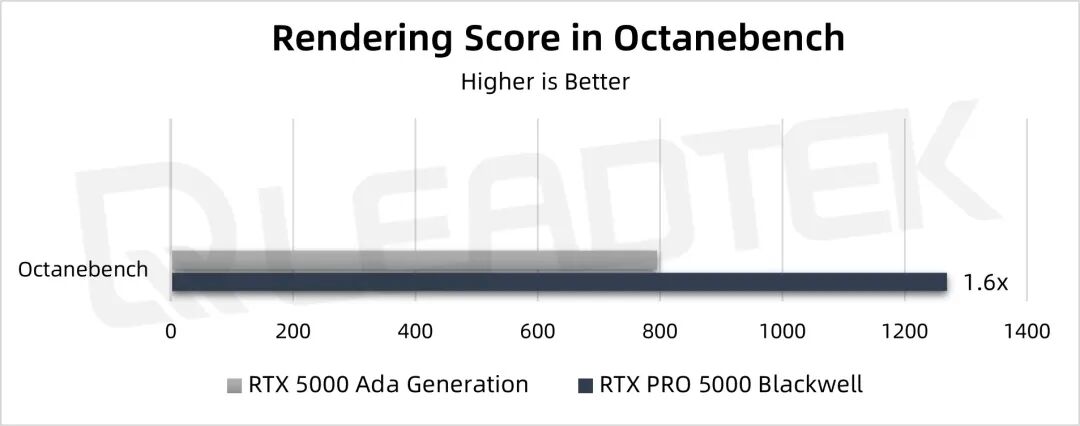
▲ 测试结果图表
从测试结果来看,在 Octane 渲染器上的性能 RTX PRO 5000 是 RTX 5000 Ada 的1.6倍。
3. AI 性能测试
在 AI 性能测试环节,我们聚焦当前主流应用场景,分别针对文生图(Text-to-Image)和大模型文本生成(LLM)展开专项评估。
-文生图测试:采用业界广泛应用的 ComfyUI 工具,使用其默认工作流参数及预设提示词,通过统计单次图像生成耗时进行性能对比。
-大模型文本生成测试:基于 MLPerf Client v1.5 基准测试套件,重点测量首 Token 生成时间(TTFT)和每秒处理 Token 数(TPS)两大核心指标。
3.1 Picture Generation Benchmark
在此项测试中,我们使用 ComfyUI Text to Picture 的工作流来测试。我们在此只关注 GPU 计算的时间来对比性能。
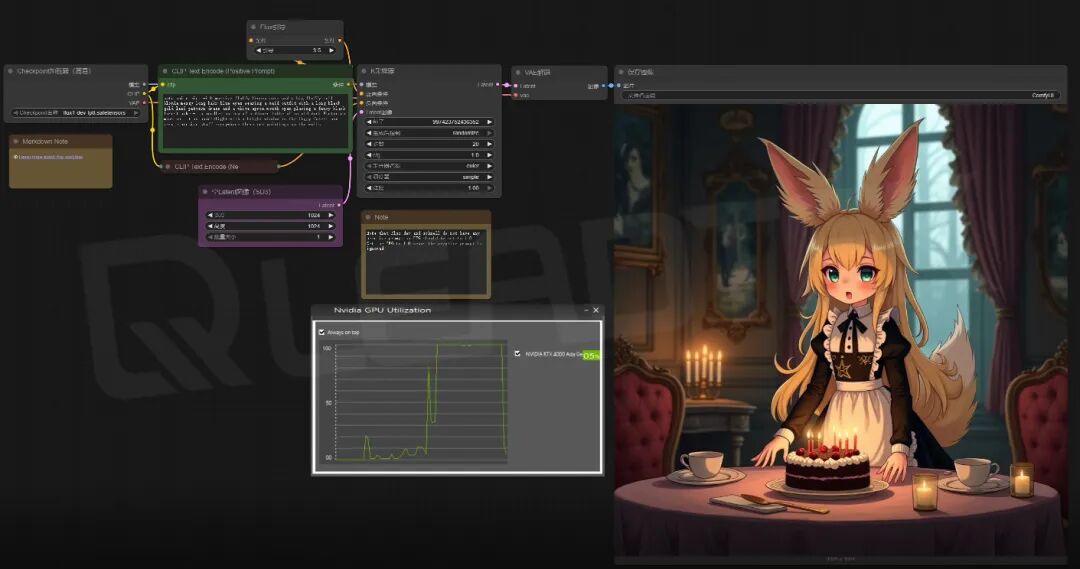
▲ RTX PRO 5000 Blackwell 测试结果截图
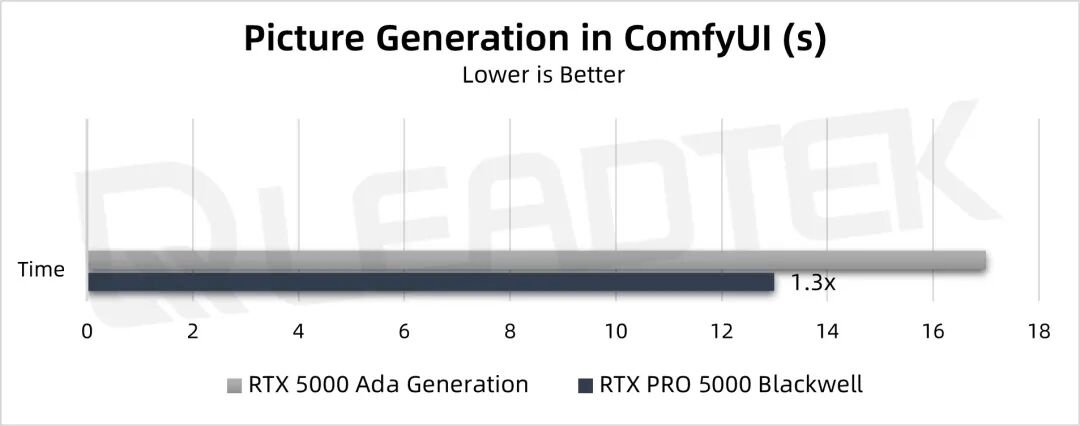
▲ 测试结果图表
从测试结果来看使用 ComfyUI 中常用的 Flux1-dev-fp8 模型进行推理性能测试,RTX PRO 5000 是 RTX 5000 Ada 性能的1.3倍。
3.2 Video Generation Benchmark
在此项测试中,我们使用 ComfyUI Text to Video 的工作流来测试。我们在此只关注 GPU 计算的时间来对比性能。
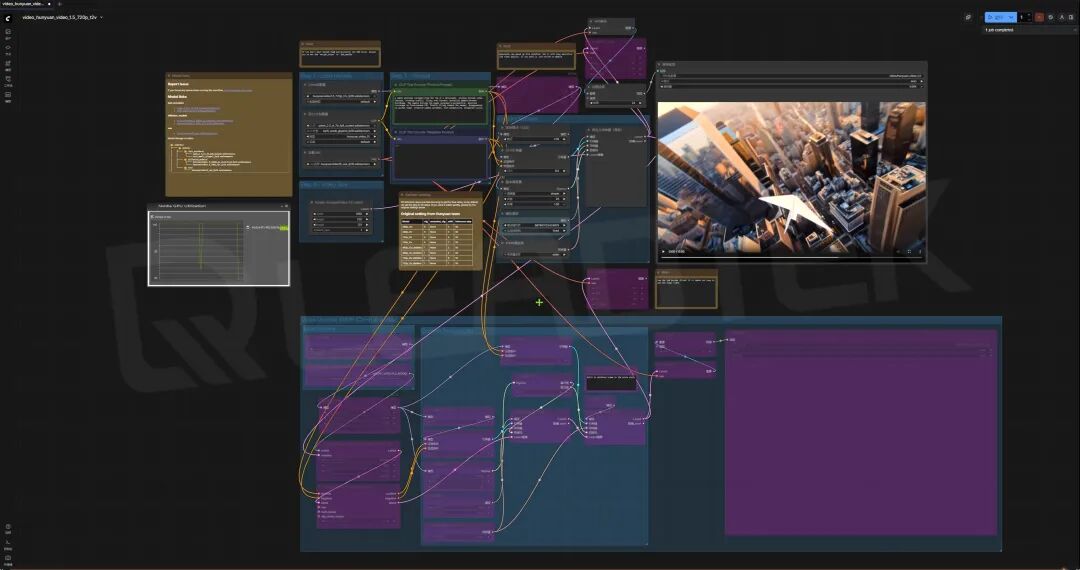
▲ RTX PRO 5000 Blackwell 测试结果截图
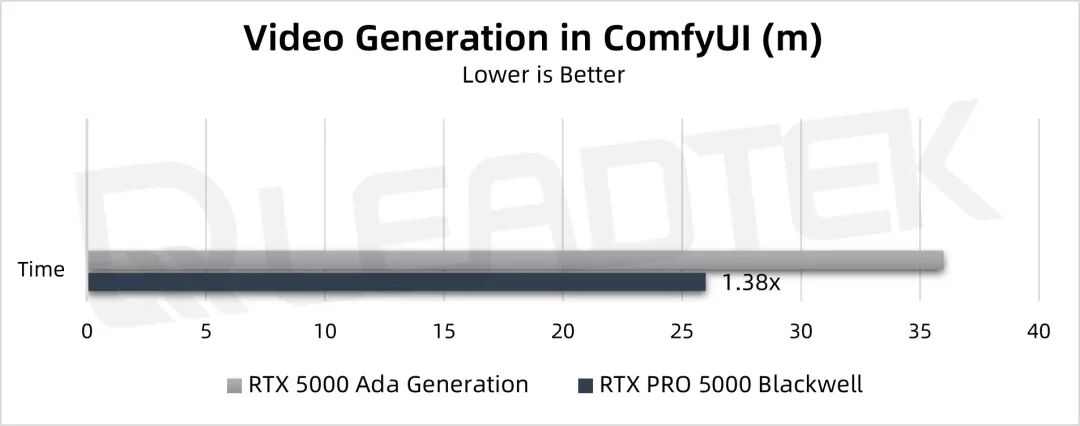
▲ 测试结果图表
Workflow 使用的是 ComfyUI 默认的采用混元大模型的文生视频默认设置。对比生成所用的时间,RTX PRO 5000 Blackwell 的性能是 RTX 5000 Ada Generation 的1.38倍。
3.3 MLPerf Client v1.5 Benchmark
在软件测试环节,我们采用了多款主流语言模型(LLM)进行性能评估。大型语言模型作为当前最具影响力的生成式人工智能形态之一,能够通过自然语言交互实现多任务处理。选择聚焦 LLM 测试,源于其在客户端本地部署场景中展现出广阔应用前景,涵盖智能聊天交互、AI 代理服务及个性化信息管理等领域。因此,我们选用 MLPerf 这一权威基准测试平台,重点评估 GPU 加速大模型的首 Token 生成时间(TTFT)及每秒处理 Token 数(TPS)两大核心指标。

▲ RTX PRO 5000 Blackwell 测试结果截图
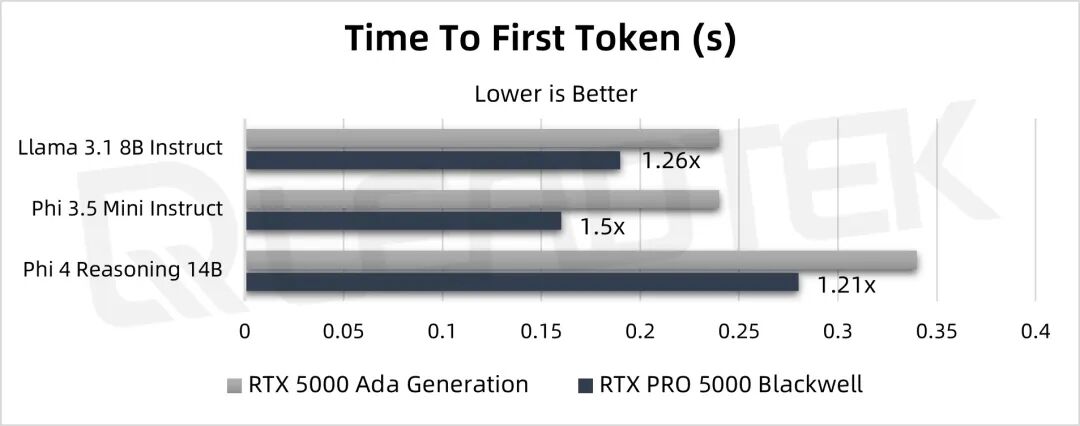
▲ 测试结果图表
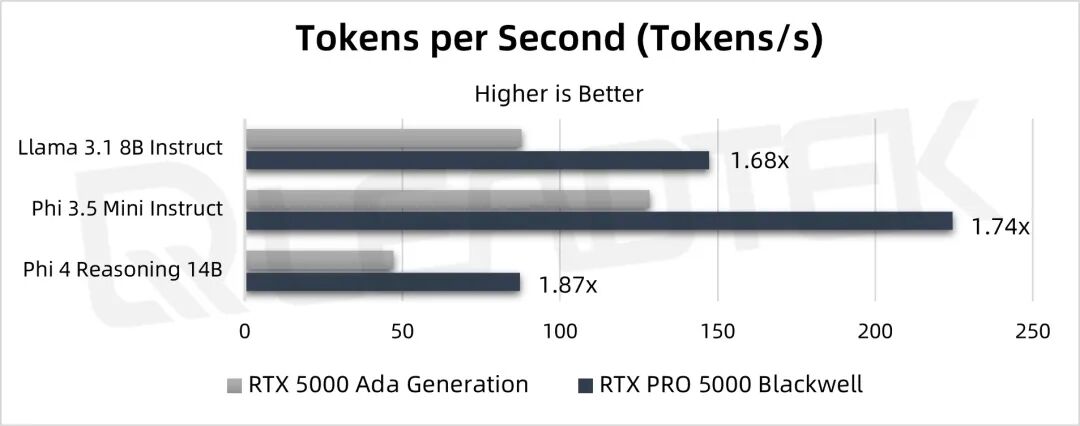
▲ 测试结果图表
从测试结果来看在大模型推理性能上,响应时间提高了20%~50%,还是每秒处理的 Tokens 数量,RTX PRO 5000 对比 RTX 5000 Ada 提高了70%~90%的性能,AI 大模型的性能提升幅度非常大。
总结

▲ NVIDIA RTX PRO 5000 Blackwell 官方渲染图
作为 NVIDIA 专业显卡产品线中的高端型号,RTX PRO 5000 Blackwell 通过配备更多 CUDA 核心与更大容量显存,展现出卓越的计算密集型任务处理能力。随着 AI 技术的持续演进,该显卡在日益丰富的 AI 应用场景中均能提供稳定高效的性能输出。
图形 API 的处理性能,OpenGL 提高了 61%,DirectX 提高了 53%,Vulkan 提高了 35%,性能提升很大。
在离线渲染方面也有了 40%~70% 的性能提升,虽然单精度浮点运算性能没有增加,但是综合渲染能力,在硬件综合提升下,仍然有了很大的提升。
在 AI 性能方面,ComfyUI 文生视频和文生图都有 30% 以上的提升。在大模型推理的应用场景中,首次响应时间提升了 20%~50%,每秒处理的 Tokens 数量,则有 70%~90% 的提升。
综上所述,NVIDIA RTX PRO 5000 Blackwell 作为高端专业 GPU 的中流砥柱,在 GPU 计算密集型应用场景中实现了显著的性能提升。尤其在大型模型推理任务中,该产品能够提供更快的响应速度,并支持更多用户并行处理,为 AI 技术在各行业的深度应用提供了强大的加速支持。在 AI 技术持续渗透各领域的今天,它无疑是加速应用落地的首选解决方案。